
就在刚刚已往不久的九月尾,有“ChatGPT最强平替”之称的Anthropic拿到了亚马逊的一笔总价40亿美元的投资,之后不久他们就揭晓了一篇论文《朝向单义性:通过词典学习剖析语言模子》(Towards Monosemanticity: Decomposing Language Models With Dictionary Learning),在这篇论文里详细论述了他们注释神经网络与大语言模子(经常被简称为LLM)行为的方式。
Anthropic之以是能有“ChatGPT最强平替”的别名,主要是由于其首创成员险些都介入开发过GPT系列的早期版本,稀奇是GPT-2和GPT-3。而众所周知GPT系列真正引人关注是从GPT-3之后的3.5最先的,老话说“罗马不是一天建成的”。而且Anthropic的AIGC产物Claude与ChatGPT相比也不逊色若干,今年炎天推出了最新版Claude 2,英国《卫报》对此谈论称“训练时以平安性为主要思量,可以称为‘合宪式AI’或‘合宪式机械人’”,一个全新的AI或机械人分类与研究也可能就将由此开启。

现在市面上盛行的LLM基本都是基于海量的神经网络而打造,而神经网络又是基于海量数据训练而来。在此基础上的AIGC,如文本、图片、视频等多模态或跨模态内容,虽然也可以保证可观的准确性且数目上也日益厚实,但可注释性始终是难以突破的难关。
举个例子,现在随便找个AI问1 1=?它们都市说1 1=2,但都无法注释这个历程是若何发生的。即便能举行简朴注释,也只是基于语义上的肤浅明白。就像我们人类睡觉时的梦乡一样,人人都市做梦也都能大致说出梦乡内容,但对梦乡的成因几千年来始终都没有合理和统一的注释。
ChatGPT等LLM经常泛起无序、杂乱、虚伪信息等情形,这种行为被称为“AI幻觉”,也就是常说的一本正经的乱说八道,主要是由于人类无法控制AI与大模子内的神经网络行为。以是Anthropic的研究对于增强LLM,甚至AI与大模子整体的准确率、平安性,降低有害内容输出的辅助都异常大,这篇论文照样很有参考和借鉴意义的。
论文链接:

01 关于神经元与神经网络
为了更好地明白Anthropic研究的意义,这里先简要先容几个基本看法。神经元是神经网络的基本组成部门,主要对数据举行输入、盘算和输出。它的事情原理是对大脑神经元事情方式的模拟,吸收一个或多个输入,每个输入都有一个对应的权重。这些输入和权重的乘积被加总,然后加上一个偏置项。获得的总和被送入一个激活函数,激活函数的输出就是这个神经单元的输出。
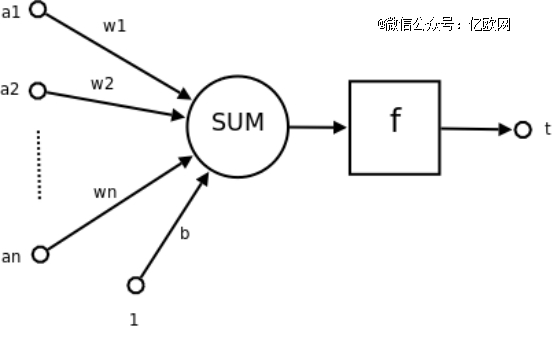
神经元事情流程示意图,其中a1-an为输入向量的各个分量,w1-wn为神经元各个突触的权重值,b为偏置项,f为转达函数,通常为非线性函数,t为神经元的最终输出效果
前面说过神经元是神经网络的基本组成形式,一定数目的神经元就可以组成一个神经网络。这种系统源于对人类中枢神经系统的考察研究与逆向应用,最初的看法早在上世纪40年月早期就提出了,1956年在一台IBM 704电脑上举行了首次实践,但往后就陷入幽静,直到1975年“反向流传算法”的发现,80年月中期“漫衍式并行处置”的头脑(那时称之为“联络主义”)最先盛行,又促使社会各界再次最先重视神经网络。进入新世纪后,稀奇是2014年泛起的“残差神经网络”看法,极大的突破了神经网络的深度限制,随着“深度学习”看法的提出和盛行,神经元与神经网络也水涨船高的愈发引人注目。
02 对LLM等大模子的主要性
前面说过现在的LLM和大模子、AIGC等,基本都要依赖神经元与神经网络才气生长壮大,能说会道的ChatGPT也正是依赖Transformer的神经网络架构开发而来。LLM使用神经网络来处置和天生文本,在训练历程中,它们会学习若何展望文本序列中的下一个词,或者给定一部门文本后续的可能内容。为了做到这一点,LLM需要明白语言的语法、语义、以及在一定水平上的上下文。
归纳综合来说,神经元与神经网络提供了处置和天生自然语言的盘算框架,而LLM则通过这个框架来明白和天生文本。这也是许多人对现在的LLM,AIGC,甚至整个AI的原理都归纳综合为“概率论 邪术”的主要缘故原由之一。
客旁观来,这种说法有些偏激但简直也有原理,由于现在的大部门大模子,包罗GPT系列在内,它们的天生原理简直可以这么归纳。
前面说过AI的事情方式可以视为对人类大脑事情方式的逆运用与模拟,而GPT之类使用的黑盒系统也在结构上模拟大脑,由海量的神经元组成。因此要想说明“可注释性”就必须要领会每个神经元在做什么。
苹果的手表、泡泡玛特的手办,真的「碳中和」了吗?
03 Anthropic的研究
Anthropic的研究是基于Transformer模子举行的一次小规模实验,将512个神经元剖析成4000多个特征,并逐个分类排序,好比DNA序列、执法专业术语、HTTP请求、营养说明等。经由试验和研究后发现,单个特征的行为比神经元行为更容易注释且可控,同时每个特征在差其余大模子中基本上都是通用的。
为了验证这一研究效果,Anthropic还确立了一个盲评系统,来对照单个特征和神经元的可注释性,由图中可见特征(紫红色)的可注释性得分要比神经元部门高了不少(青蓝色)。
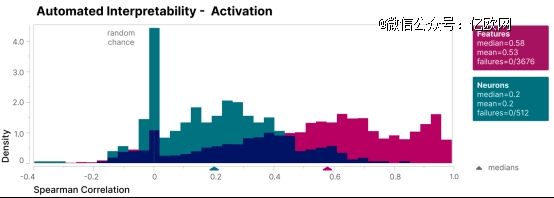
此外Anthropic还接纳了自动注释性方式,最终的效果也是特征得分高于神经元得分,不外这种方式较为庞大,此处不睁开,详见其论文。
Anthropic的这项研究简直意义特殊,不外早在几个月前,OpenAI也曾做过类似的事情。在今年五月初,OpenAI在官网宣布博客文章《语言模子可以注释语言模子中的神经元》(Language models can explain neurons in language models),其中说到:“我们使用GPT-4自动编写LLM中神经元行为的注释,并为这些注释评分,现在将GPT-2中每个神经元的这些(不*的)注释和分数的数据集宣布出来。”那时读过这篇论文的人,险些都为OpenAI的奇思异想而感应震撼,头皮发麻。
那时之以是有这项研究,主要是为了回覆ChatGPT火遍全球的同时引起的一个问题:“生长到今天这一步,AI是怎样实现这么壮大的功效的?”
为了回覆这个问题,OpenAI那时的做法可以简朴的归纳综合为“用黑盒注释黑盒”。而且OpenAI的这次研究功效,倒也不失为后续AI与大模子等相关企业举行研究探索了新的偏向,自然意义特殊。前面说过AI可以视为是对大脑事情原理的逆运用,而LLM等大模子都使用的黑盒结构也都由海量神经元组成,也是在模拟大脑。
那时OpenAI给出的注释历程分三步:
给GPT-4一个GPT-2已有的神经元,由GPT-4展示相关的文本序列和激活情形,发生一个对此类行为的注释;
再次使用GPT-4,模拟被注释的神经元会做什么;
对照二者的效果,凭证匹配水平对GPT-4的注释举行评分。
最终OpenAI示意GPT-4注释了GPT-2中的所有约30万个神经元,然则绝大多数的现实得分都偏低,只有委屈一千多个的得分高于0.8,这意味着神经元的大部门*激活行为都是这一千多个神经元引起的。
看来AI或许也在有意无意间遵照“二八定律”。那时这项研究功效很快在全球各大手艺平台也引起了普遍关注。有人感伤AI进化的方式愈发先进:“未来就是用AI完善AI与大模子,会加速进化。”也有人指斥其得分甚低:“对GPT-2的注释尚且云云,那若何领会GPT-3.5和GPT-4内部结构呢?但这才是许多人现在更关注的谜底。”
虽然电脑是模拟人脑的原理而发现,但人脑的结构实在并不高效,好比没有存储装备,神经元的通讯也是通过激素或荷尔蒙等化学方式来举行,相当的别扭。这种“落伍”的“元器件”竟然能给人类云云高的智慧,说明人脑的壮大主要在于架构。
当前探索智能的本质也是脑科学研究的中央义务之一,是领会人类自身、解密头脑与智能成因的科学探索需要。脑科学与AI息息相关,既可以提升我们人类对自身隐秘的明白,也可以改善对脑部疾病的认知水平,同时相关科研功效也可以为生长类脑盘算,突破传统电脑架构的约束提供依据。
但在当下,类脑盘算还具有着伟大的空间,守候着科研气力填补。当下千亿量级参数的大模子已经习以为常了,若是把参数看成神经的突触,大模子对应人脑的神经元,只有1亿个。而1亿个神经元与人脑千亿级其余神经元,中央的差距有千倍之多,而这一差距或许也是走向AGI人类科学必须跨越的鸿沟。
OpenAI和Anthropic做的这些研究,也在无形中给我们的科学手艺提高展示了一种可能性:当未来对的AI变得越发壮大,甚至有一无邪的逾越人类,它也能在后续更多的前沿科技上为人类提供辅助;而对智能的研究,在生物大脑之外也有了AI系统作为新的研究工具,这也为破解智能之谜带来了新的希望。