
2024年6月19日,「中科驭数」宣布了其研发的第三代DPU芯片K2-Pro。作为一款纯国产的高性能解决方案,K2-Pro展现了其在云盘算、智能盘算、及高性能盘算等领域的应用潜力。
借此时机,我们也来分享一些中科创星关于DPU领域的看法和看法。
01
数字经济开启算力时代
据华为GIV展望,2030年人类将迎来YB数据时代,全球算力规模到达56ZFlops,平均年增速到达65%。与此同时,我国不仅拥有位居全球第二的算力规模,且盘算产业的规模已经占有了电子信息制造业的20%以上。换言之,在这个由移动互联网、信息手艺和物联网配合编织的网络时代,我们正履历着数据量的指数级发作的趋势。
然而,对现代IT基础设施来说,这一升级历程就像一个不停扩大的黑洞,其需求缺口正在不停放大。
详细来看,算力基础设施的架构由三个相互依存的支柱组成的:盘算、存储和网络。这三大手艺领域,就像数字天下的三大基石,配合支持着我们日益增进的数据处置需求。
当前,存储手艺的提高让我们能够以亘古未有的速率和容量保留信息,网络手艺的生长则让数据传输变得加倍迅速和可靠。
但当我们将眼光转向数据中央的盘算能力时,我们会发现一个逐渐展现的问题:只管存储和网络在不停提高,但数据中央的盘算能力却似乎最先跟不上数据增进的措施。尤其是随着数据中央规模的扩大和网络流量的增添,传统的网络接口卡(NIC)可能无法知足高速数据处置的需求。
打个譬喻,数据中央又像一个周详的神经系统,将数据中央内所有的盘算和存储单元慎密地毗邻在一起,组成了一个高效的“交通枢纽”,它的效率和能力直接影响着数据中央的性能。这就像一个高速运转的引擎,突然遭遇了燃料供应不足的问题。
另一方面,软件界说网络(SDN)和网络功效虚拟化(NFV)的兴起确实对数据中央的网络架构和硬件资源提出了新的要求。例如,由于SDN和NFV需要在服务器上运行多个虚拟网络功效,如Open vSwitch(OVS),这增添了对CPU焦点的需求。若是每个焦点都需要高效的网络毗邻,那么支持CPU的网络带宽需求将从25Gbps增添到更高,如100Gbps、200Gbps甚至更高。
正是在上述靠山下,我们越来越需要一种能够应对大量数据和庞大义务的网络装备,这就是智能网卡(smart NIC)泛起的缘故原由。
与传统网卡相比,智能网卡不仅能够处置高速网络数据流,还能通过编程实现特定功效,从而减轻CPU的肩负。
换言之,传统网卡就像是一个没有特殊手艺的邮差,它只能将邮件(数据包)送到你的门口(服务器),之后所有的分类和处置事情都需要你家里的管家(CPU)来完成。这在邮件不多的时刻还好,但若是邮件数目激增,管家就会异常忙碌。
而智能网卡就像是一个多才多艺的邮差,不仅能送信,还能在路上就帮你分类好邮件,甚至能凭证你的喜欢预处置一些邮件内容。这样,当你收到邮件时,大部门事情已经完成,管家只需要做最后的整理。
近年来,随着无人驾驶、机械人等手艺的快速生长,人工智能市场正迅速膨胀,但我们面临的挑战也越来越大,好比,需要处置的数据量急剧增添,模子变得加倍庞大,智能网卡也遇到了它的瓶颈。
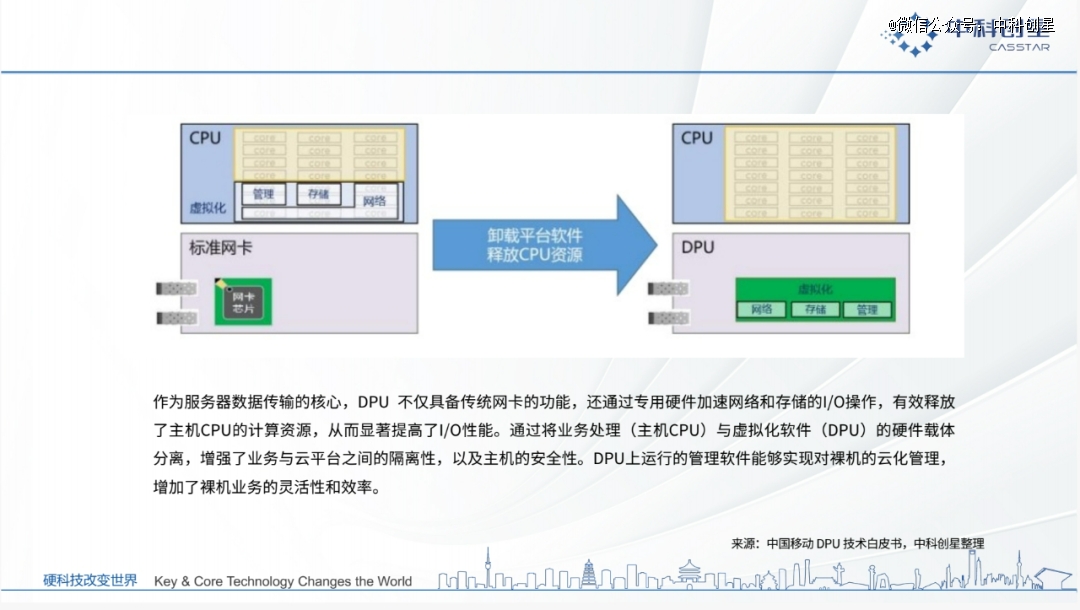
为了突破这些瓶颈,我们需要更壮大的盘算能力。于是,智能网卡最先向更高级的形式——DPU(Data Processing Unit)演进。

02
算力的“第三驾马车”
如前文所言,随着数字化时代的到来,我们对盘算的需求像搭上火箭一样飙升,但CPU和GPU在忙于处置大量数据时,却不得不分心去做一些“杂活”,好比数据的存储和传输。
然而,相关研究指出,CPU在忙碌的事情中,约莫有30%的时间实在是被这些非盘算义务占用了。这就像是让一位科学家在实验室里同时还要处置清洁事情,显然会影响他的研究效率。
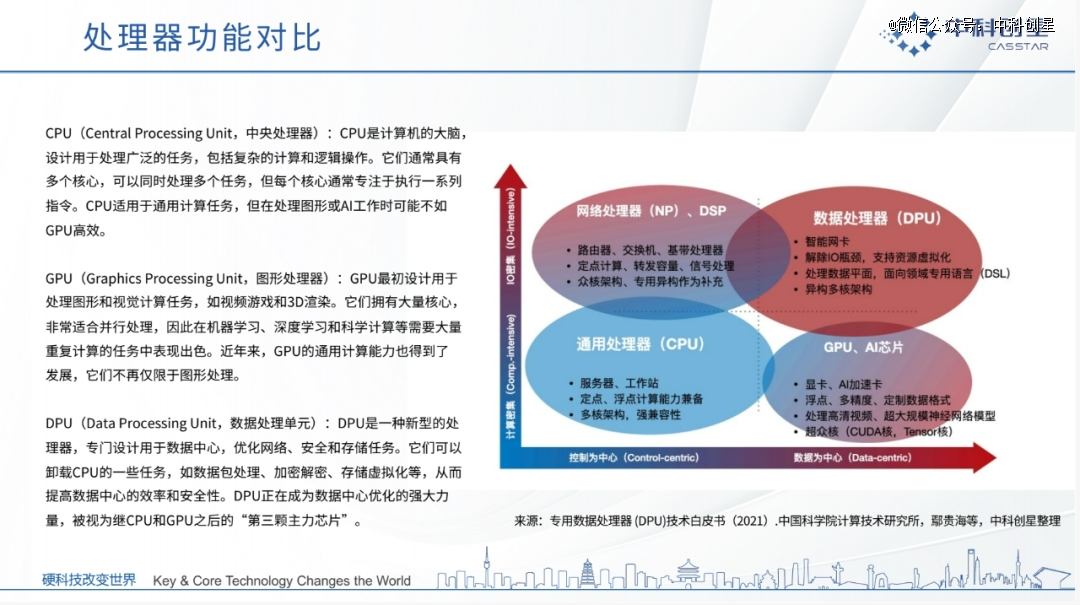
反观DPU,作为一种新型的专用处置器,它的目的就是卸载CPU和GPU的非盘算义务,让它们能够更专注于执行焦点盘算义务,从而释放CPU和GPU的盘算能力,实现算力基础设施以盘算为中央的生长目的。
现实上,从设计理念来看,DPU的设计方式被称为“领域专用架构”(DSA)——就像定制的衣服更贴合身体,DPU在处置特界说务时也加倍轻车熟路。例如,一个针对网络数据处置优化的DPU,可以比通用CPU快10倍以上。
此外,DPU另有一个像变形金刚一样的手段——“软件界说”。这意味着DPU的功效不是一成稳固的,而是可以通过软件更新来调整,就像给DPU装上了一个天真的大脑。
最后,DPU另有一个主要特征,那就是它支持资源的虚拟化。这就好比把一个大蛋糕切成许多小块,每小我私人都能分到一块,而且可以凭证自己的口味选择差其余口味。在数据中央,这意味着可以将一个大的盘算资源池支解成多个小的部门,每个部门都可以自力使用,从而提高资源的行使率。据Cisco的数据显示,通过虚拟化手艺,企业可以削减高达40%的服务器数目,同时提高资源行使率。
因此, DPU的主要焦点功效也就得以凸显:
1.算力释放:在传统的盘算机架构中,CPU就像一个忙碌的交通指挥员,需要不停地在内核和应用之间转达数据,这就像是在岑岭时段指挥交通,很容易造成拥堵,会消耗大量的时间和精神,可导致高达30%的性能消耗。使用DPU后,CPU可以更高效地事情,削减性能瓶颈,阻止因负载过大而泛起故障。
元气森林摸着农夫山泉过河
2.算力卸载:算力卸载是DPU的另一个主要功效,它就像是给CPU减负的神奇助手。想象一下,若是一个工人既要搬运重物,又要操作庞大的机械,他很快就会筋疲力尽。CPU已往就是这样,它不仅要处置焦点的盘算义务,还要处置网络、存储、平安和治理等辅助功效,这些义务消耗了大量的算力资源。DPU通过接受这些辅助功效,使CPU能够专注于它最善于的盘算事情。据研究,DPU可以削减CPU在处置网络和存储义务时约莫40%的算力消耗。
3.算力扩展:已往,依赖缩小芯片的工艺尺寸来提升CPU的性能,但当工艺到达3纳米级别后,这种提升变得越来越难题。面临后摩尔时代的挑战,业界最先转向漫衍式系统,通过扩大盘算集群的规模、提升网络带宽和降低网络延迟来提升数据中央的整体算力。DPU在这个历程中饰演了主要角色,通过优化网络通讯,有用阻止了网络拥塞,降低了跨节点通讯的延迟,提升了盘算效率。

简而言之,DPU通过其定制化的设计理念、软件界说的天真性和资源虚拟化的支持,为数据中央带来了更高的效率和性能,成为现代盘算基础设施的要害组成部门。
例如,在数据中央领域,DPU能够快速处置网络数据包,就像是在岑岭时段指挥交通的能手,确保数据流的流通无阻。DPU还能加速存储操作和平安加密义务。凭证现实案例,使用DPU可以提升数据中央的处置速率高达50%,同时降低能耗约20%。
再例如,在人工智能领域,稀奇是在深度学习模子的推理历程中,DPU能够快速处置图像和语音识别等义务,实现靠近实时的AI应用。一部门研究显示,DPU在AI推理义务中能够提供比传统CPU快10倍以上的处置速率,这对于自动驾驶这类需要快速响应的应用场景至关主要。
03
DPU的生长现状及未来趋势
凭证赛迪照料宣布的《中国DPU行业生长白皮书》显示,2020年全球DPU产业市场规模为30.5亿美元,预计到2025年将增进至245.3亿美元,年复合增进率为51.73%。同期,中国DPU市场规模预计将到达565.9亿元人民币,5年复合增进率到达170.6%。可以说,全球DPU市场处现在正处于景气周期之内。
为此,海内外企业在DPU方面举行了相当水平的探索。外洋方面,英伟达(NVIDIA)、完善(Marvell)、英特尔(Intel)等几家国际芯片巨头集结研发团队并投入巨额资金,竞相推出DPU产物。
例如,2021年英特尔推出了基础设施处置器IPU(Infrastructure Processing Unit) Mount Evans——Mount Evans 融合了英特尔多代FPGA SmartNIC的研发履历,提供高性能网络和存储虚拟化卸载以及可编程数据包处置引擎,支持防火墙和虚拟路由等功效。
再例如,英伟达在2022年宣布了第三代BlueField,并具备连续演进能力,演进蹊径以集成AI算力、增强 ARM能力以及升级网络速率带宽为主。
在此靠山下,中国的DPU市场也正迅速崛起,展现出强劲的增进势头,一批有潜力的DPU芯片制造商最先崭露头角。而中科创星在这个领域也已经举行了一定的结构。
以中科创星天使轮项目「中科驭数」为例。早在2018年,「中科驭数」就展现出了其前瞻性头脑,创新性地提出了软件界说加速器的手艺蹊径(SDA),不仅研发了KPU(Kernel Processing Unit,核处置器)这一专用盘算芯片架构,且还接纳了软硬件协同的方式,构建了一个以KPU为焦点的硬件数据库(Database)、网络运算加速(Network)和人工智能加速(AI)的“DNA”一体化加速产物系统。
正是基于软件界说KPU架构,「中科驭数」于2022年乐成宣布了的K2 DPU芯片——K2 DPU芯片设计以数据为中央,集成自研FlashNOC™流式片上互联架构,可实现数百个处置核互联,在2TB/S数据带宽下保证零壅闭数据传输。同时,在网络方面集成了2路10/25/100GE接口,主存储集成了四路DDR4,带宽可达50GB/S,容量达128GB。
经由1年半左右的研发升级,「中科驭数」又于克日宣布了第三代DPU芯片K2-Pro。据宣布会信息显示,本次「中科驭数」宣布的K2-Pro接纳自研架构,融合了网络卸载、存储卸载、平安卸载、盘算卸载等功效,旨在提升数据中央的网络吞吐量、降低传输延时,提高数据传输效率,支持数据中央规模的连续增进,可以为云盘算、智能盘算、高性能盘算等场景提供纯国产高性能网络解决方案。
作为「中科驭数」上一代DPU芯片K2的量产版本,在数据处置能力上,K2-Pro的包处置速率提升至80Mpps,是原K2的两倍,这使得它在网络麋集型应用中能够提供更高的吞吐量和更低的延迟。
其次,K2-Pro还增强了对庞大营业的支持,集成了包罗网络卸载、流表卸载、存储卸载和RDMA网络卸载在内的多种硬件卸载引擎。这些引擎使得K2-Pro能够以轻量级控制面处置庞大的营业,将庞大服务网格的性能从400微秒提升至30微秒以内,实现了显著的性能飞跃。
另一方面,K2-Pro通过PPP(多协议处置)、NP(网络处置器)内核以及P4可编程架构,实现了营业与算力的天真扩展,使用户能够凭证需求动态调整系统设置,从而实现算力的自由伸缩。
K2-Pro还提供了周全的片上和板级治理系统,增强了资源治理和系统稳固性。在DPU的庞大应用场景中,K2-Pro的能耗降低了30%,实现了低功耗运行,进一步优化了能效比。

芯片之外,针对DPU的特定需求,如IO、数据处置能力、控制逻辑等,「中科驭数」还开发了专用扩展指令集KISA(Kernel-based Instruction Set Architecture)。KISA的创新之处在于,它首次在指令集层面支持迅速异构处置,通过统一的指令集实现对多种异构处置焦点的有用治理和调剂。
现在,KISA指令集包罗基础架构和针对DPU的专用处置扩展指令,如包剖析、数据转发和表查询等。KISA已被应用于25个差其余应用场景,累计支持数百个用例,经由了充实的实践验证。
宣布会上,「中科驭数」首创人鄢贵海示意:本次宣布K2-Pro意味着对DPU的重新界说,而中科驭数的目的是为算力基础设施提供一流的DPU产物,解决算力资源的弹性扩展、高效互连、加速盘算、统一运维等要害问题,买通数据中央算力的“堰塞湖”。
基于此,「中科驭数」不仅将DPU视为单一芯片,而是从三个维度重新界说其价值:1)架构决胜,用*进的芯片架构来重新界说DPU芯片架构;2)软件护城,用最高兼容性来重新界说DPU的软件系统;3)平台上门,用*的成本让客户接入DPU规模化部署与营业验证。以上三方面的内容将组成「中科驭数」在算力基础设施领域的“芯云设计”。我们做芯,是为了服务云。手中有芯,心里有云。
04
结语
自18世纪的“蒸汽时代”到“电气时代”再到现在的“信息时代”,每一次革命都是对人类潜能的一次伟大释放,而我们现在正处于一个由数字手艺引领的创新与革命的新历史历程中。
在这场“智能时代”的革掷中,人工智能、大数据、云盘算、物联网——这些手艺正如细胞盘据般加速迭代,正在逐步推动社会进入一个全新阶段,这也意味着我们对算力提出了更高的要求。
相关研究解释,随着算力指数的提升,数字经济和GDP的也会随之增进。因此,我们可以预见的是,在这场算力革掷中,DPU以其高手艺、高智能、高性能的优势将有望成为推动革命发作的要害气力之一。